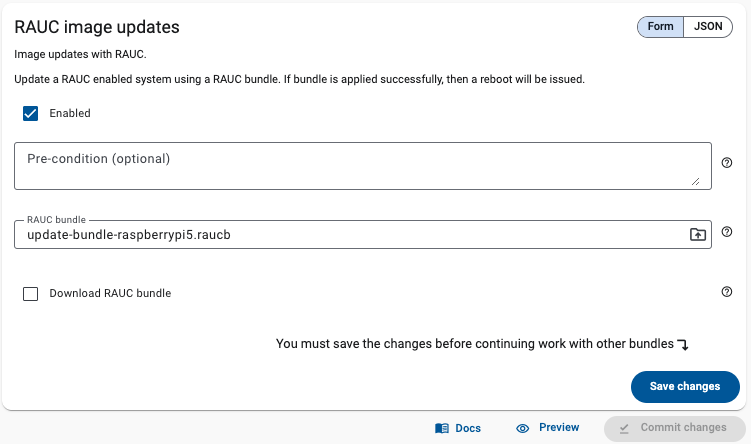
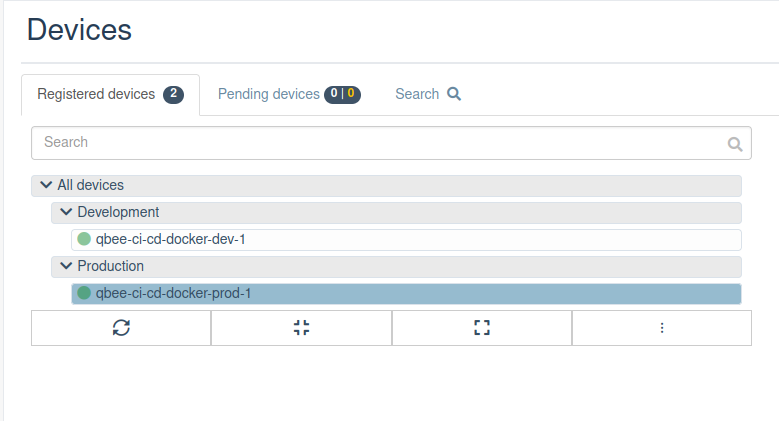
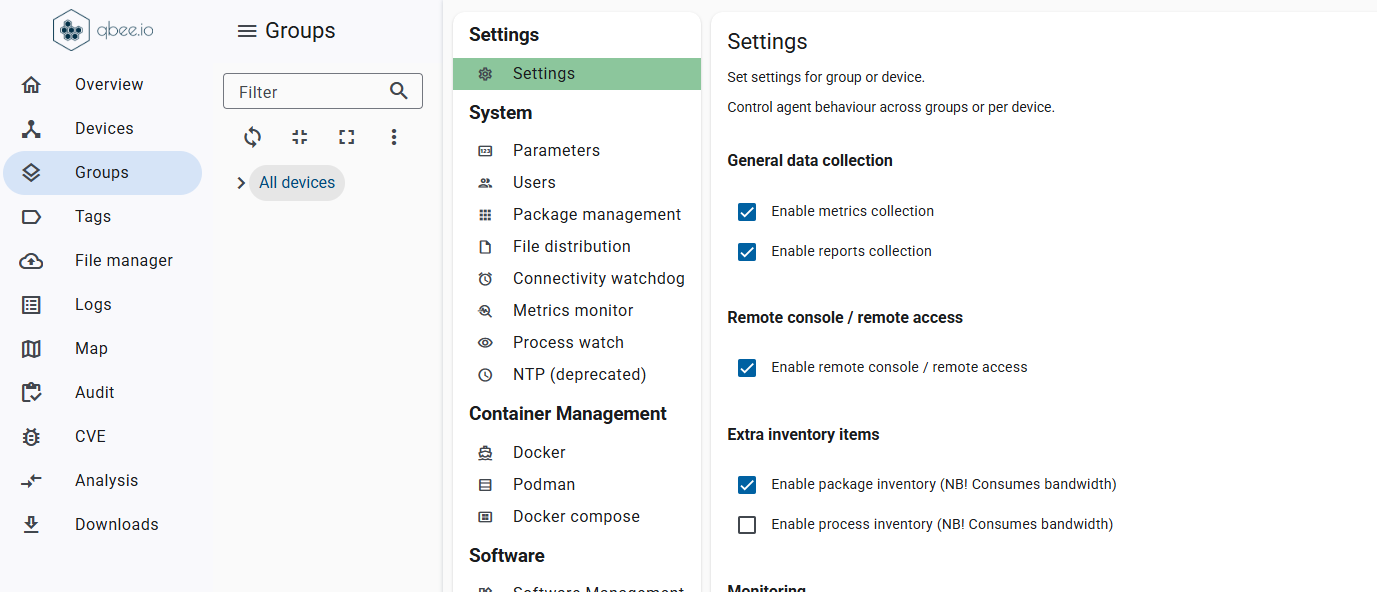
Update your entire fleet with confidence
Deliver updates to any number of devices, whether you manage dozens or tens of thousands.
With Qbee, every rollout becomes predictable, smooth, and completely stress-free. Instead of worrying about what might go wrong, you can trust that each device gets exactly what it needs, exactly when it needs it.